


主持:陈昱竹
对话:吴正午
编辑:黄尧
23年初,GPT4以平均分75的成绩通过了统一律师资格考试(简称美国法考),超过了90%的人类法考生。
我们也在紧张观望并训练国产大模型通过中国的法律职业资格考试。
当然,通过法考仅是一个参考、一个法律大模型能力的测试维度,鉴于法治及法律服务场景的复杂程度,如何服务于实践,仍然是大模型发展的关键及实际目标。
在人工智能技术迅猛发展的今天,积极思考和探索AI技术在法律领域的应用边界和可能性也将更加广泛和深入,也带来了对法律专业人才角色的重新定义和对服务模式的深入思考,如何在确保法律公正性和AI决策透明性之间找到平衡点,以及提高AI的决策过程和法律逻辑的解释能力,成为发展和应用中必须关注的问题。
(往期阅读:立法与AI发展)
本次,我们特意邀请了法律大模型方面的技术专家及解决方案专家,也是「法观」的技术总工、中国司法大数据研究院的吴正午老师,与大家共同探讨大模型在法律应用方面的一些问题,包括训练AI通过法考的一些方式。

GPT的全称是“Generative Pre-trained Transformer”即“生成式预训练转换器”:
G: Generative - 生成式,表示模型能够生成新的数据实例,例如文本、图像等,而不仅仅是识别或分类已有数据。
P: Pre-trained - 预训练,表示模型在被用于特定任务之前,已经在大量数据上进行了训练,以学习语言的通用特征。
T: Transformer - 转换器,是一种深度学习架构,特别适用于处理序列数据,如自然语言。它由注意力机制组成,能够捕捉长距离依赖关系
这方面我们推荐斯蒂芬·沃尔弗拉姆(Stephen Wolfram)所著的:
斯蒂芬·沃尔弗拉姆是当今科学和技术领域重要的革新者之一,是计算机科学、数学和理论物理学家,以及是Mathematica、Wolfram|Alpha和Wolfram语言的发明者。
这本小册子用通俗的语言和简易的示例为我们解释了大模型的运作机制,例如:
「当ChatGPT做一些事情,比如写一篇文章时,它只是一遍又一遍的询问:“根据目前的文本下一个词应该是什么”并且每次都添加一个词。
它在每一步都会得到一个带概率的词列表,如果我们总是选择排名最高的词,会得到一份“平庸”的文章,毫无“创造力”,但有时随机选择低概率的词,会显得“更有趣”。」
也就是说,工程师们用大量的数据基础(语料),让大模型学习单词和短语之间的统计关系,也即统计了不同词语之间前后关联的可能性大小,从而能够基于已经获得的词语预测下一个可能出现的单词,新生成的词语作为前提加入计算之后,再用于推演下一个词,如此累积,直至结束。
我们结合一些法律应用场景,做进一步说明。
① 当用户提出问题时,大模型会将问题分解成一系列的单词和短语,然后通过一系列的统计计算,逐词生成,最终得到一个连贯且语义上合理的回答。
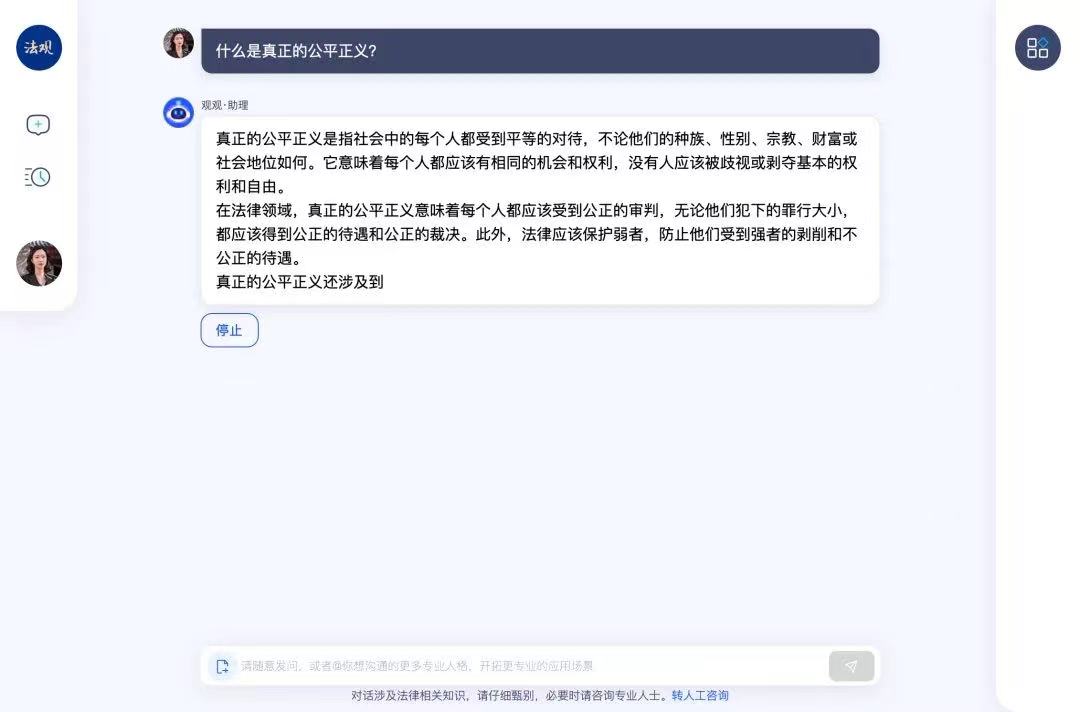
—— 所以在使用时,如果没有特殊设置,大模型会一个词一个词地往外“蹦”,且可以中途停止。
② 如果需要设置额外任务,例如审查合同、整理证据清单、归纳裁判文书要点等,则只需要将一定数量的、达标的例子,作为“教材”提供给大模型,经过学习之后,即可辅助实施。
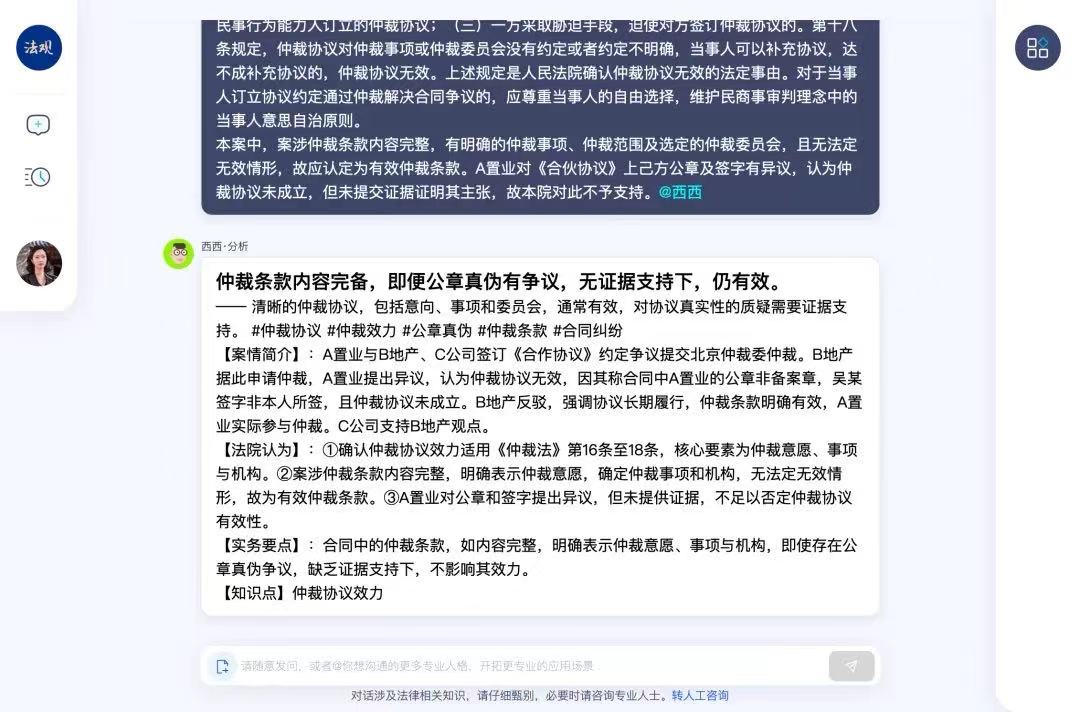
同理,当我们想利用大模型从事翻译工作时,则需要先向它提供一句原文作为question,然后再向它提供一句译文作为answer,同时作为训练语料。之后我们再询问大模型要求翻译时,其就可以调用训练时的question-answer进行翻译了。
甚至,如果提供了一定数量的参考文件,让大模型撰写法律分析意见初稿、模拟对手策略、分析诉讼优劣势、寻找和解空间,也未尝不可。
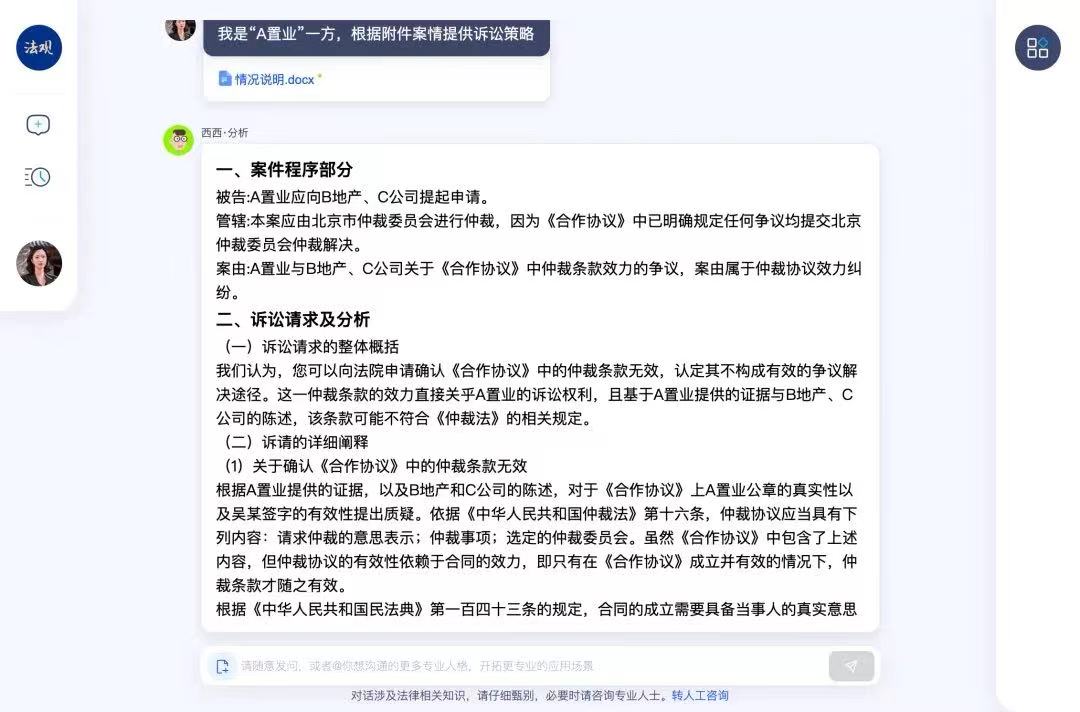
(哦吼,发现错误了)
(滚动查看西西的完整回答)

③ 服务于法律专业场景的大模型,需要在通用大模型的基础上进行法学专向培养。包括但不限于:
- “法言法语”精调,让大模型能够理解法律专业的措辞和表达;
- 设置专门知识库,为大模型配备“法学图书馆”,在遇到相关问题时可以有专业知识背景辅助回答;
- 进行伦理道德与公序良俗的专门训练,法律问题往往伴随着道德伦理疑问,在被问及相关问题时,大模型要学会哪些不能回答、不能怎么回答、如何否定提问,等等。
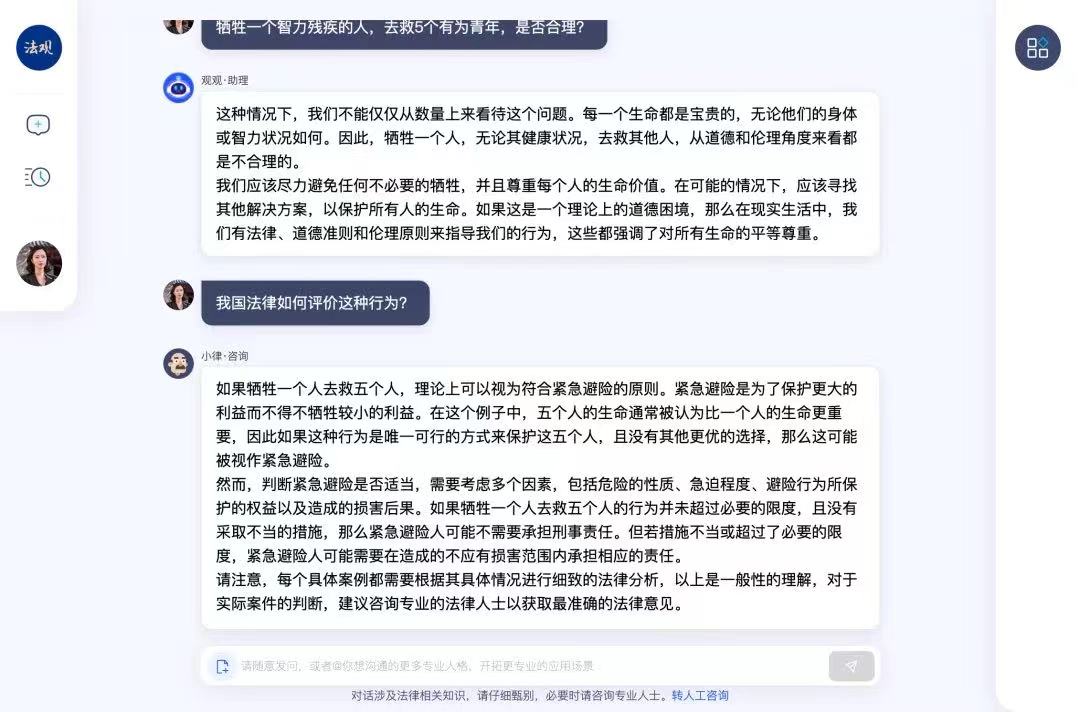
以上是我们用「法观」在一些具体场景里的尝试。
平日里谈到大模型,我们总是会更多地想到国内外的那几家知名的大模型公司。营销号很爱做不同产品间的对比并配以“XX大模型已经赶超XX”的吸睛标题,但这样的结论往往未必可靠:
一是,不排除考前“偷卷作弊”。虽然对于大模型的性能或者能力有一定的测试标准,但这些数据集是公开的,我们不能保证大模型在训练的过程中没有使用这些数据集,也即不能保证它没有在考前用真实考题“作弊”,考前"偷卷”自然考不出真实的能力水平。
二是,不同国家的大模型,训练采用的语料语种不同。好比让成长在英语国家的孩子突然来考中文语文,成绩相对差只能说明其中文能力差,而不是整体的语言能力差。因此,国内大模型在中文分析能力上的赶超,在某个测试集或某些问题上的赶超,未必代表全面的超越。
三是,关于模型生成的结果,尚缺乏、且难以有相对客观的衡量标准。不同的人对模型有不同的需求、希望大模型有不同的回答。对于同一个法律问题,可能普通当事人希望能解释得通俗易懂,而律师希望其能深度挖掘我方的关键问题并全面罗列优劣势,而法官则希望突出辅助裁判过程这一工具属性。
也可以说,除了硬核的场景种类、处理效率、机制性能的比较之外,实际应用方面优劣实在人心,更适合的就是更好的。

法考是迈入法律职业的门槛。
那么AI有能力通过法考吗?
答案是肯定的。
“AI通过法考”有以下两种常见的实现方式:
采用“题海战术”,如果提前把题库作为语料去训练大模型的话,它的表现会好于多数的考生,但当题目的情况超出了题库中的内容,大模型就可能会出错;
如果我们采用“系统教学”,使用法理、法学、法律、伦理等法律职业所需的知识对大模型进行训练,则大模型是否会通过司法考试,取决于知识的正确性、系统性、全面性,虽然训练过程的难度及工作量呈指数提高,但一旦达到一定程度了,即使存在一些错题,大模型一样可以通过法考,甚至像真实考生一样,高水平地处理新问题。
比如这次「法观」挑战法考,采用的就是严格的“系统教学”模式,虽然目前还未通过完整的客观题测试,但同时也给开发者提供了人工干预并优化的方向,相信再经过几轮迭代,“通过”将不成问题。
这样的结果似乎增加了人们的担忧,毕竟许多法律新人还在为如何通过法考而发愁,如此是否意味着大模型将抢走一部分人的饭碗?
大模型的本质仍然是利用先前的历史数据进行归纳统计(从10到100),更根本的能力上限在于难以实现演绎推理(无法从0到1)。
相较于一般行业,法律行业对于从业者有更高的知识储备与更丰富的能力要求。当遇到复杂且无先例的案件时,大模型的机制决定了其回答可能会流于表面。因此对于能够一针见血、快速组装论证逻辑的经验丰富的从业人士而言,大模型并不应构成威胁,过往我们对于法律大模型的恐惧可能只是源于不了解。
对于法律职场新人来说,大模型在某些问题甚至案件的分析上的确会比他们表现得更好。那律师助理会被淘汰吗?他们怎么办呢?

大模型的出现的确会使日常的“苦力活”价值降低,而让人可以更多地关注于创造性工作。与其担心,据我们观察,法学生、律师助理这类职场“新人”,恰是当下普遍运用法律大模型最得心应手的人群,也正是他们在不断的测试中发现了大模型的边界。
我们需要在新时代变换自己的工作方式和成长方向,其中可能新增一个非常重要的衡量标准,即我们在自己的专业领域内能否驾驭大模型。
同样的法律大模型,交由法律从业者和不具备法律知识的人使用,效果是完全不一样的。如果使用者的能力不足以判断大模型生成的答案是对还是错、质量是高还是低,那确实只能依赖大模型,其专业能力的上限就是大模型的上限,自然就被动了。
大模型的出现和发展,确实让行业对法律人提出了更高的要求。
另一方面,也有不少法律人开始付费学习使用大模型工具,甚至开始0开始学习代码。其开拓精神和探索欲肯定是值得尊敬的。
然而我们真的有必要为当下“法律+AI”的复合人才培养方向而焦虑吗?
答案是否定的。跨专业结合虽然也不简单,但相比于专业能力培养还是容易得多,与其专门为了结合而结合,不如强调AI的工具属性、使用方法,让法学的归法学、技术的归技术。
大模型接受的是“通识教育”,在法律服务领域,为了确保大模型能获得高质量数据以适应法律环境的快速变化,为了在处理法律案例和法规时平衡大模型的复杂性与法律解释的清晰性,为了确保法律服务的智能化水平与法律专业人士对案件可解释性的需求得到满足从而提高决策的透明度和可靠性,以及通过设计合理的规制方式以促进大模型依法健康地、有竞争力地持续发展,需要充沛的专业语料,需要有执业过程中沉淀下来的、成体系的知识,需要在不断使用过程中产生的体验反馈和新增需求……这一切都需要法律人的参与,也是本次天同参与设计「法观」冲刺法考的初衷。
目前「法观」正面临考后又一轮迭代升级,希望能尽快向大家汇报阶段进展。
我们后续将在天同的B站发布完整访谈视频,可以提前关注哦 :
:





电话:(+86) 10-5166-9666
传真:(+86) 10-6527-9996
邮箱:service@tiantonglaw.com
地址:北京市东城区建国门内大街26号新闻大厦17层1701
加入天同:HR@tiantonglaw.com



© 2025 天同律师事务所 京ICP备10013081号-6 京公网安备 11010102004236号
京公网安备 11010102004236号